
Level Up Your Python Skills for Data Science
======================================================
As a data professional, you’re probably comfortable with Python programming. But are you following the best practices when working on data science projects with Python? Though it’s easy to learn Python and build data science applications with it, it’s perhaps easier to write code that is hard to maintain. To help you write better code, this article explores some Python coding best practices that help with dependency management and maintainability.
1. Use Virtual Environments for Each Project
Virtual environments ensure project dependencies are isolated, preventing conflicts between different projects. In data science, where projects often involve different sets of libraries and versions, virtual environments are particularly useful for maintaining reproducibility and managing dependencies effectively.
 Virtual environments ensure project dependencies are isolated.
Virtual environments ensure project dependencies are isolated.
2. Add Type Hints for Maintainability
Because Python is a dynamically typed language, you don’t have to specify the data type for the variables that you create. However, you can add type hints—indicating the expected data type—to make your code more maintainable.
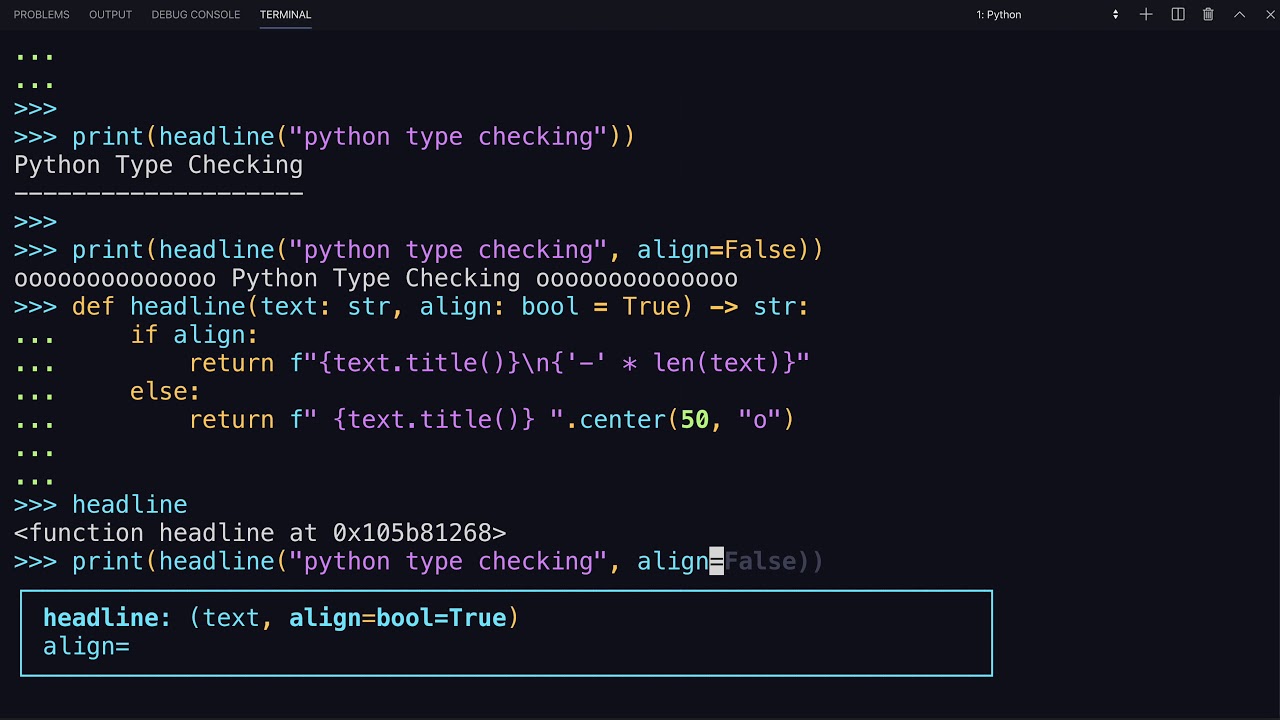 Type hints make your code more maintainable.
Type hints make your code more maintainable.
3. Model Your Data with Pydantic
Previously, we talked about adding type hints to make code more maintainable. This works fine for Python functions. But when working with data from external sources, it’s often helpful to model the data by defining classes and fields with expected data types.
Modeling data with Pydantic makes your code more maintainable.
4. Profile Code to Identify Performance Bottlenecks
Profiling code is helpful if you’re looking to optimize your application for performance. In data science projects, you can profile memory usage and execution times depending on the context.
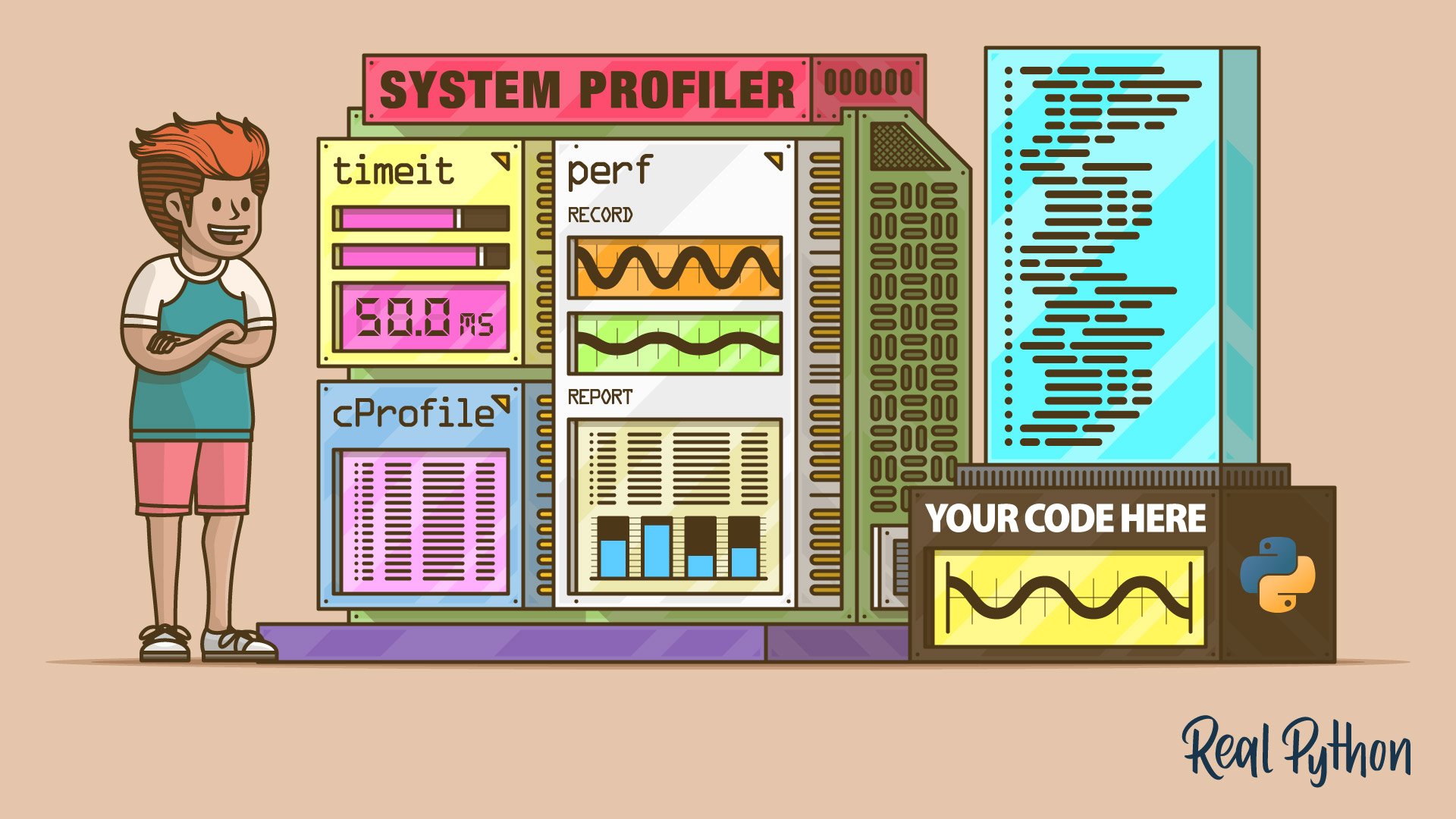 Profiling code helps identify performance bottlenecks.
Profiling code helps identify performance bottlenecks.
5. Use NumPy’s Vectorized Operations
For any data processing task, you can always write a Python implementation from scratch. But you may not want to do it when working with large arrays of numbers. For most common operations—which can be formulated as operations on vectors—you can use NumPy to perform them more efficiently.
 NumPy’s vectorized operations make data processing more efficient.
NumPy’s vectorized operations make data processing more efficient.
Wrapping Up
In this article, we have explored a few Python coding best practices for data science. I hope you found them helpful. If you are interested in learning Python for data science, check out Python for Data Science.












{kind=link}