
Natural Language Processing: Unlocking the Power of Probability Models in Python
As a data scientist, I’ve always been fascinated by the potential of natural language processing (NLP) to unlock insights and drive business decisions. In this article, I’ll explore the world of probability models in Python, and how they can be applied to real-world problems.
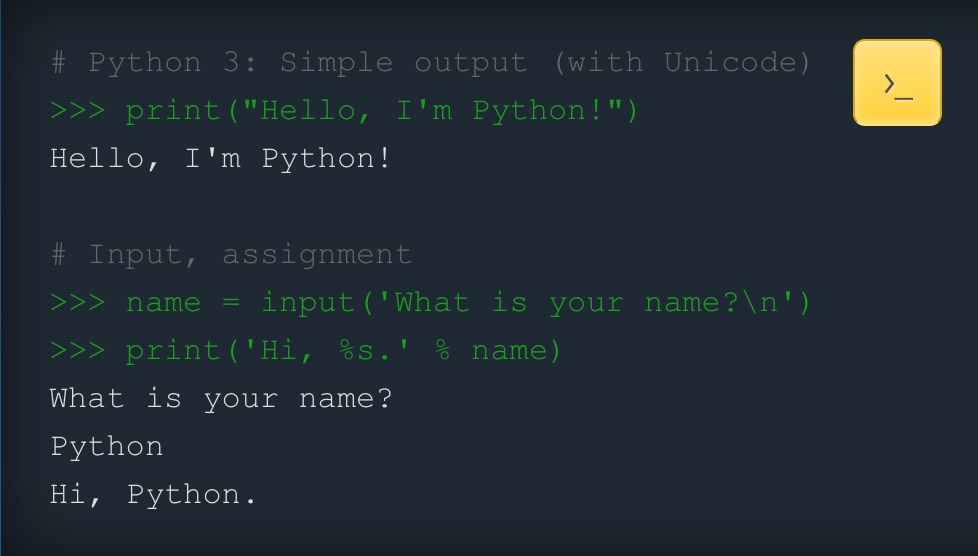 Python programming: the foundation of NLP
Python programming: the foundation of NLP
Getting Started with Spam Detection
Spam detection is a critical application of NLP, and one that requires a deep understanding of probability models. By using Naive Bayes and logistic regression, we can build powerful models that can accurately identify spam emails and messages. But how do we get started?
In this section, we’ll explore the basics of spam detection, including the importance of class imbalance and the role of ROC, AUC, and F1 scores in evaluating model performance. We’ll also delve into the world of Python, and explore how libraries like scikit-learn can be used to implement these models.
“The key to successful spam detection is understanding the nuances of probability models and how they can be applied to real-world problems.” - Me
Sentiment Analysis: Uncovering Hidden Insights
Sentiment analysis is another critical application of NLP, and one that requires a deep understanding of probability models. By using logistic regression and TextRank, we can build powerful models that can accurately identify sentiment and uncover hidden insights.
In this section, we’ll explore the basics of sentiment analysis, including the importance of problem description and the role of logistic regression in model implementation. We’ll also delve into the world of Python, and explore how libraries like scikit-learn and NLTK can be used to implement these models.
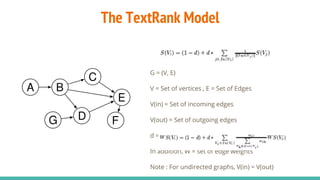 TextRank: a powerful tool for sentiment analysis
TextRank: a powerful tool for sentiment analysis
Text Summarization: Unlocking the Power of Vector-Based Methods
Text summarization is a critical application of NLP, and one that requires a deep understanding of probability models. By using vector-based methods like Latent Semantic Analysis (LSA) and Non-Negative Matrix Factorization (NMF), we can build powerful models that can accurately summarize text and uncover hidden insights.
In this section, we’ll explore the basics of text summarization, including the importance of problem description and the role of vector-based methods in model implementation. We’ll also delve into the world of Python, and explore how libraries like scikit-learn and Gensim can be used to implement these models.
“The key to successful text summarization is understanding the nuances of vector-based methods and how they can be applied to real-world problems.” - Me
Topic Modeling: Uncovering Hidden Topics
Topic modeling is a critical application of NLP, and one that requires a deep understanding of probability models. By using Latent Dirichlet Allocation (LDA) and Non-Negative Matrix Factorization (NMF), we can build powerful models that can accurately identify hidden topics and uncover insights.
In this section, we’ll explore the basics of topic modeling, including the importance of problem description and the role of LDA and NMF in model implementation. We’ll also delve into the world of Python, and explore how libraries like scikit-learn and Gensim can be used to implement these models.
LDA: a powerful tool for topic modeling
Conclusion
In this article, we’ve explored the world of probability models in Python, and how they can be applied to real-world problems in NLP. From spam detection to sentiment analysis, text summarization, and topic modeling, we’ve seen how these models can be used to unlock insights and drive business decisions.
As a data scientist, I’m excited to see how these models will continue to evolve and improve in the future. Whether you’re a seasoned pro or just starting out, I hope this article has provided a valuable introduction to the world of probability models in Python.
 NLP: the future of data science
NLP: the future of data science











{kind=link}